Google DeepMind社によって開発された囲碁プログラムAlphaGoが、2016年3月15日に世界最強の囲碁棋士と言われたイ・セドル氏に勝利したことで、ディープラーニングは多くの人々や企業の注目を集めることとなりました。
以前から海外ではディープラーニングが利用できるツールはあったものの、日本語に対応していなかったりしたため、手軽に利用できるものはありませんでした。しかし、SONYが提供したNeural Network Consoleは日本語のマニュアルもあり、初心者にも手がつけやすいものとなっています。
以前はディープラーニングの開発となるとPythonでプログラムを構成するケースが多かったが、Neural Network Consoleは直感でモジュールをドラックするだけで学習モデルの構築が可能です。
ここではNeural Network Consoleの使い方を紹介し、この記事ではサンプルプログラムを動作させるまでを説明します。
ディープラーニングに関する記事はこちら
インストール
まず下記リンクから登録ページへ移動
ここでは「Windowsアプリではじめる」を選択して進めていきます。
 「Windowsアプリではじめる」をクリックすると下記画面になるのでメールアドレスを入力
「Windowsアプリではじめる」をクリックすると下記画面になるのでメールアドレスを入力
「上記に同意して送信」をクリック
 登録したメールアドレスにダウンロードページのURLが記載されているので、ダウンロードする。ダウンロード時間は5分~10分程度。
登録したメールアドレスにダウンロードページのURLが記載されているので、ダウンロードする。ダウンロード時間は5分~10分程度。
ダウンロードページは
https://getconsole.dl.sony.com/******** というURLになります。
 ダウンロードが完了したら、neuarl_network_console_120.zipを解凍します。
ダウンロードが完了したら、neuarl_network_console_120.zipを解凍します。
5分程度かかる見込みです。
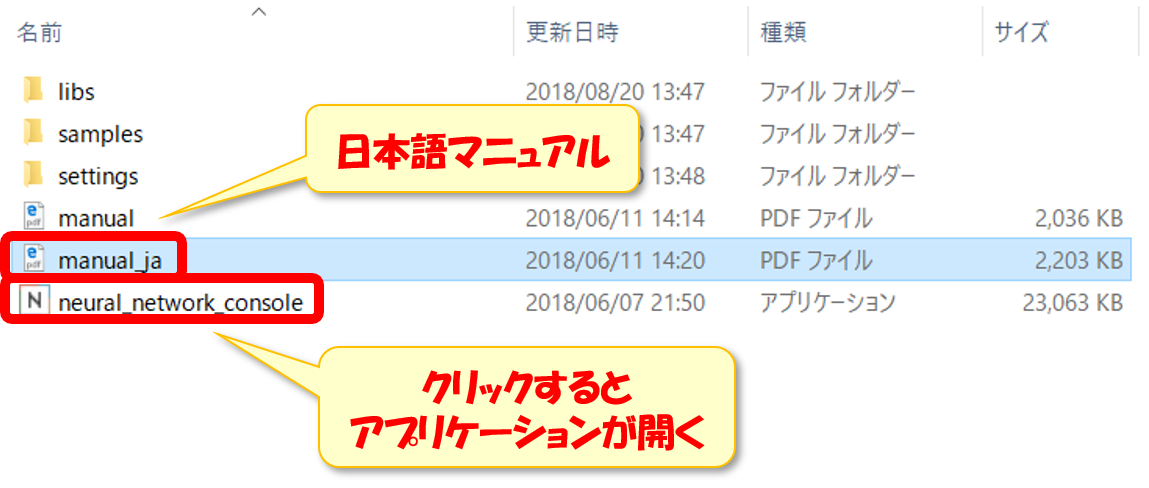
 解凍したフォルダを見ると下記のようになっています。
解凍したフォルダを見ると下記のようになっています。
「manual_ja」が日本語マニュアル
「newral_network_console」をクリックするとアプリケーションが開きます。
アプリケーションを起動
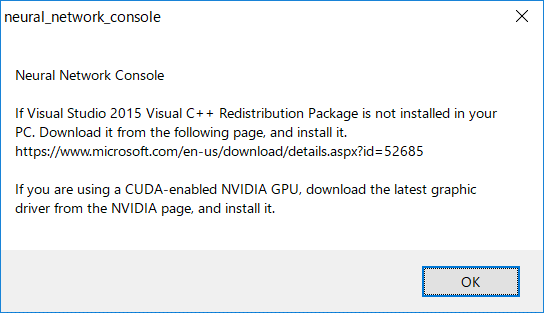
アプリケーションを開くと下記メッセージが表示されるが「OK」をクリックして進む。
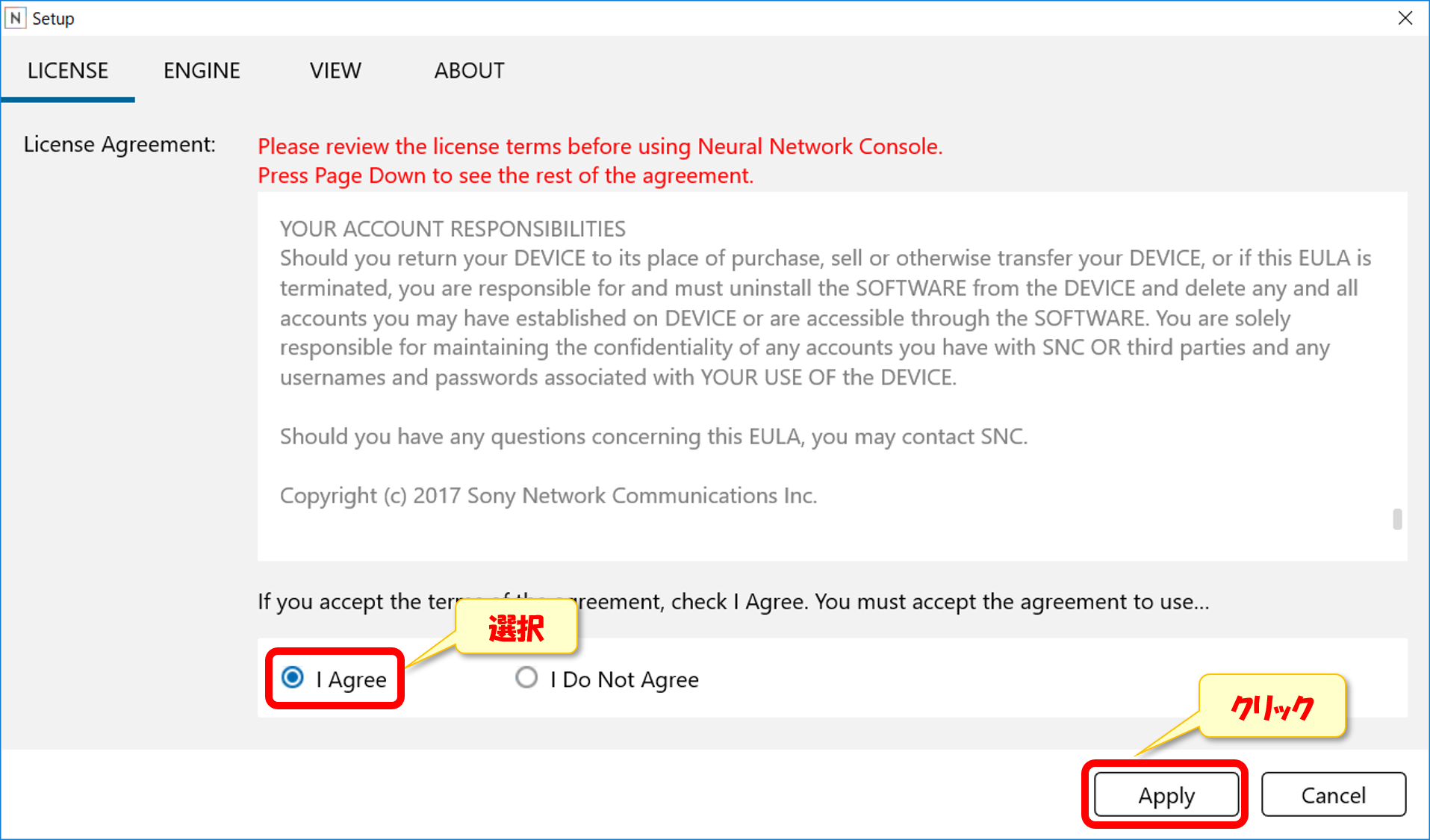
 下記の画面の表示される。「I Agree」を選択し、「Apply」をクリック
下記の画面の表示される。「I Agree」を選択し、「Apply」をクリック
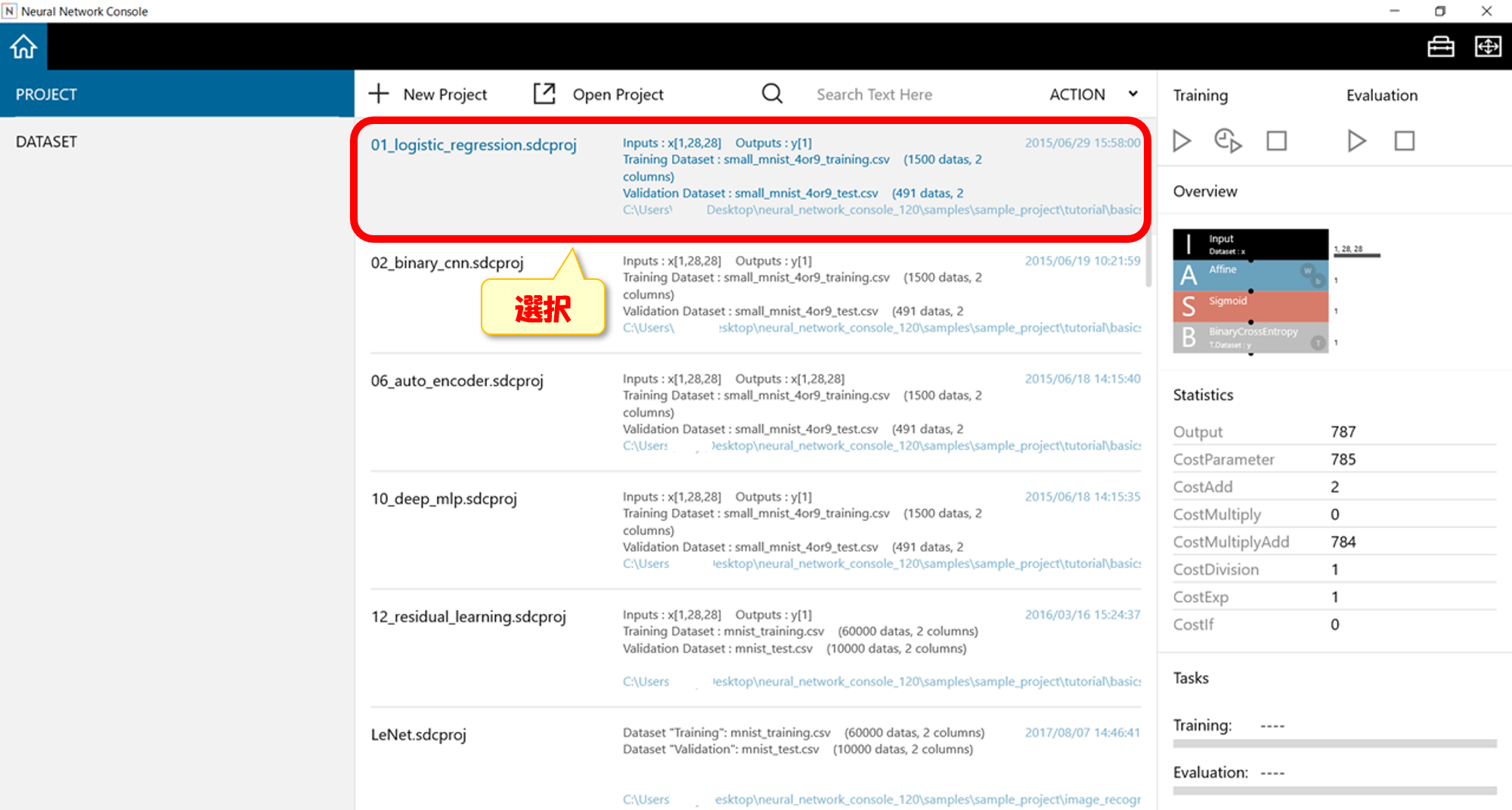
 サンプルプログラムを動作させるため、下記画面の赤線内をクリックする。
サンプルプログラムを動作させるため、下記画面の赤線内をクリックする。
サンプルプログラムは定番の数字認識プログラムです。
下記メッセージが表示される。「はい」をクリック。
 手書きデータが読み込まれるのでしばらく待機
手書きデータが読み込まれるのでしばらく待機

学習モデル
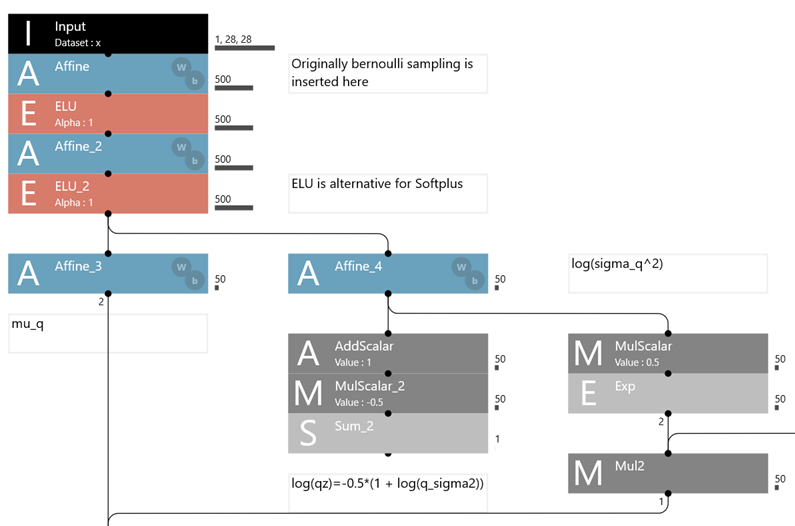
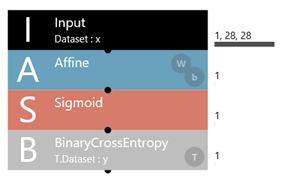
今回のサンプルプログラムは数字認識であり、そのなかでも「4」と「9」の認識に特化したものです。Neural Network Console内のモデル下記のような形で表現されます。
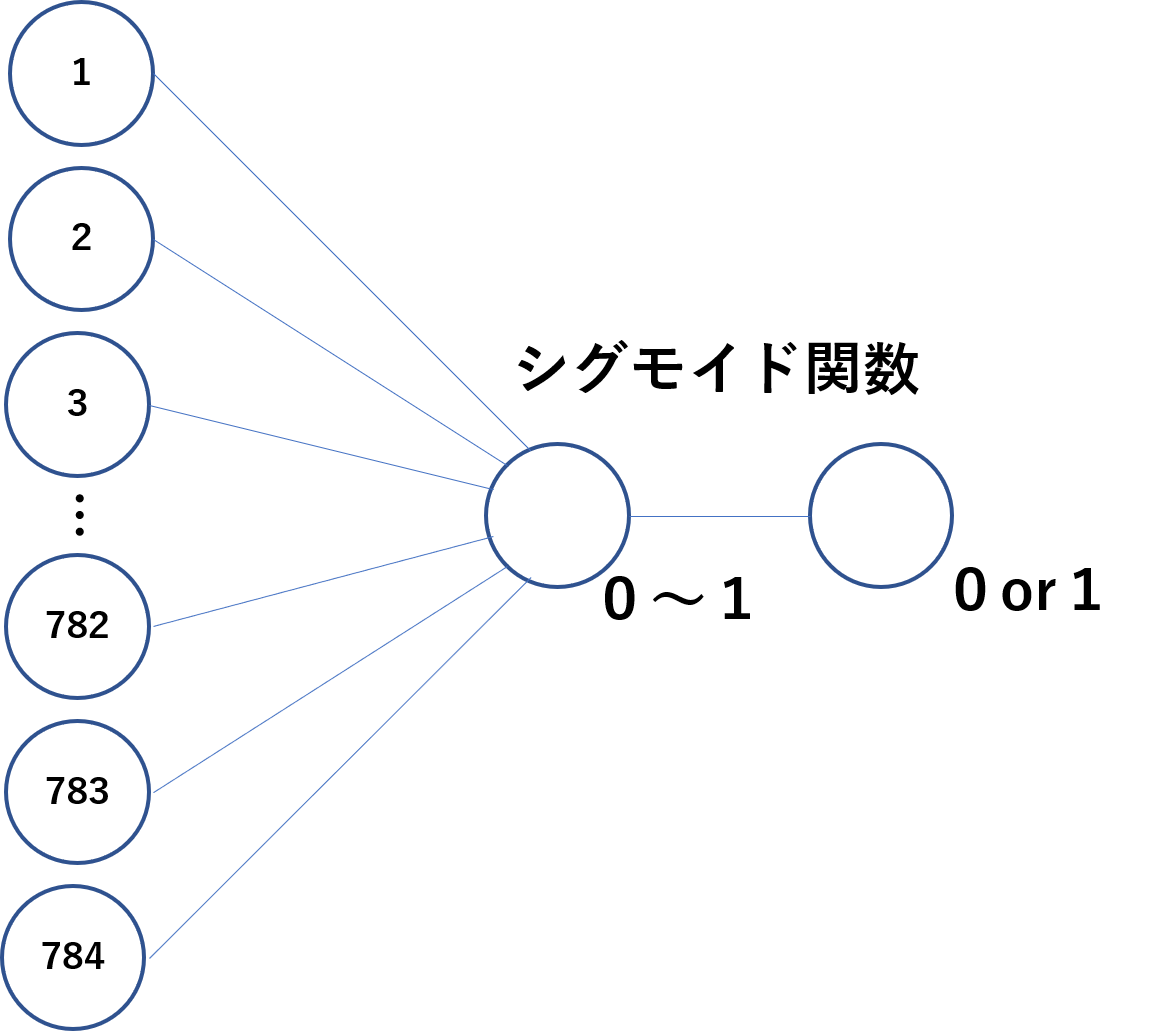
まず入力データについて説明する。今回の入力は28×28の行列である。例えば9の手書きデータは下記のようなデータで表示されていると考えてよいです。。つまり28×28=784の入力があるということになります。
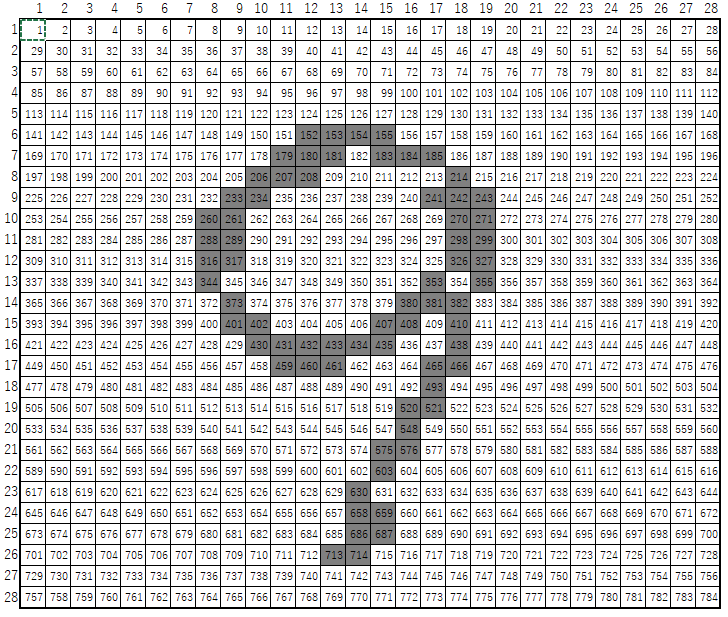
次にモデルについて説明する。今回のモデルでは「Affine」,「Sigmoid」,「BinaryCrossEntropy」の横の添え字が1なので、下記のようなモデルになります。活性化関数はシグモイド関数です。
サンプルプログラムの設定
それではサンプルプログラムの設定画面の説明を行います。まず、下記画面の「DATASET」をクリック。
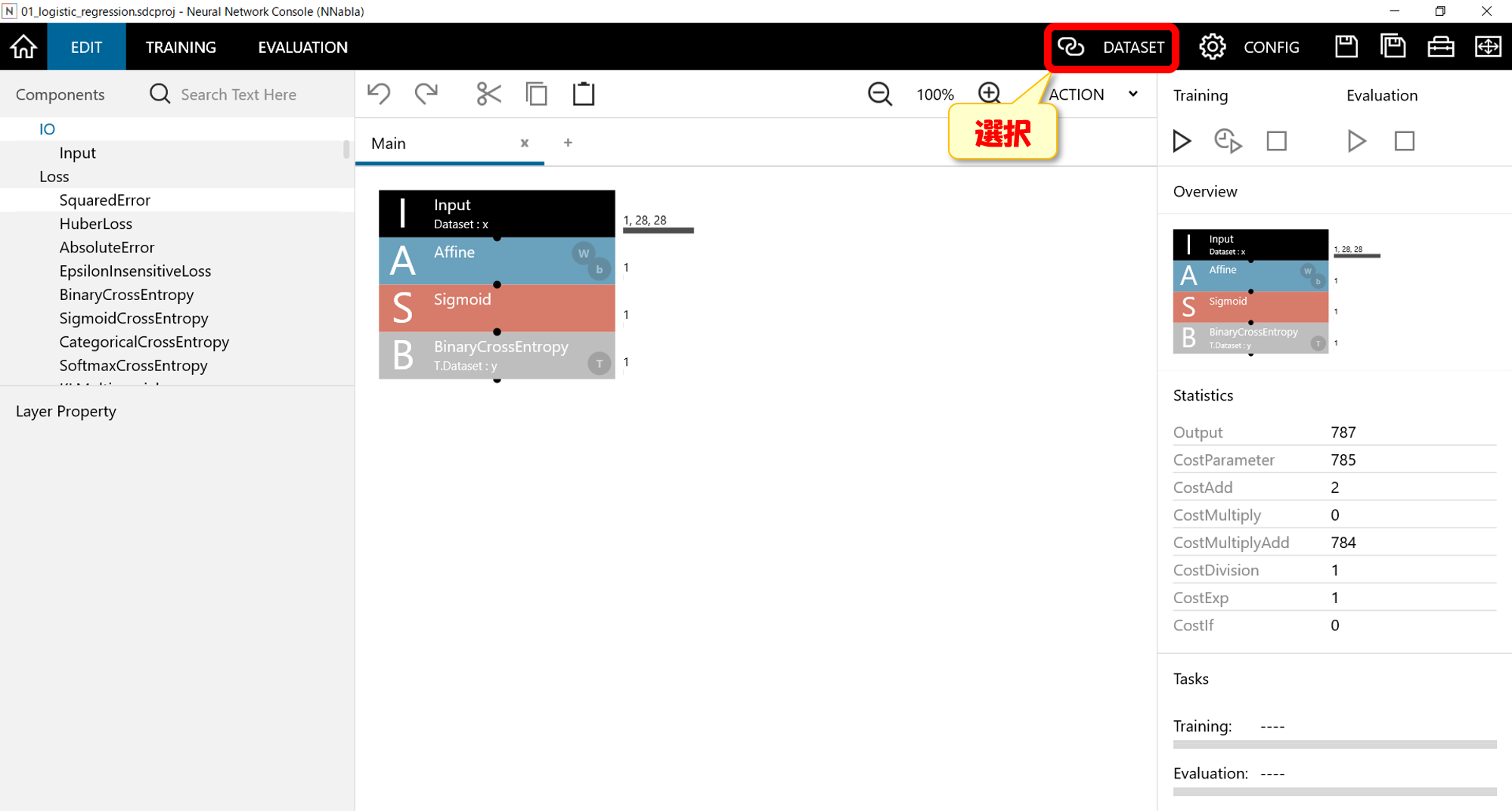 すると下記画面のようになる。入力xには数字のデータ、yには正解ラベルが関連付けてある。「4」の場合は0であり、「9」の場合は1となっています。
すると下記画面のようになる。入力xには数字のデータ、yには正解ラベルが関連付けてある。「4」の場合は0であり、「9」の場合は1となっています。
また左側のTrainingを見るとNum Data = 1500となっているので、訓練データ数は1500です。Validationを見るとNum Data = 500となっているので、訓練データに使わない検証のみデータが500あることになります。
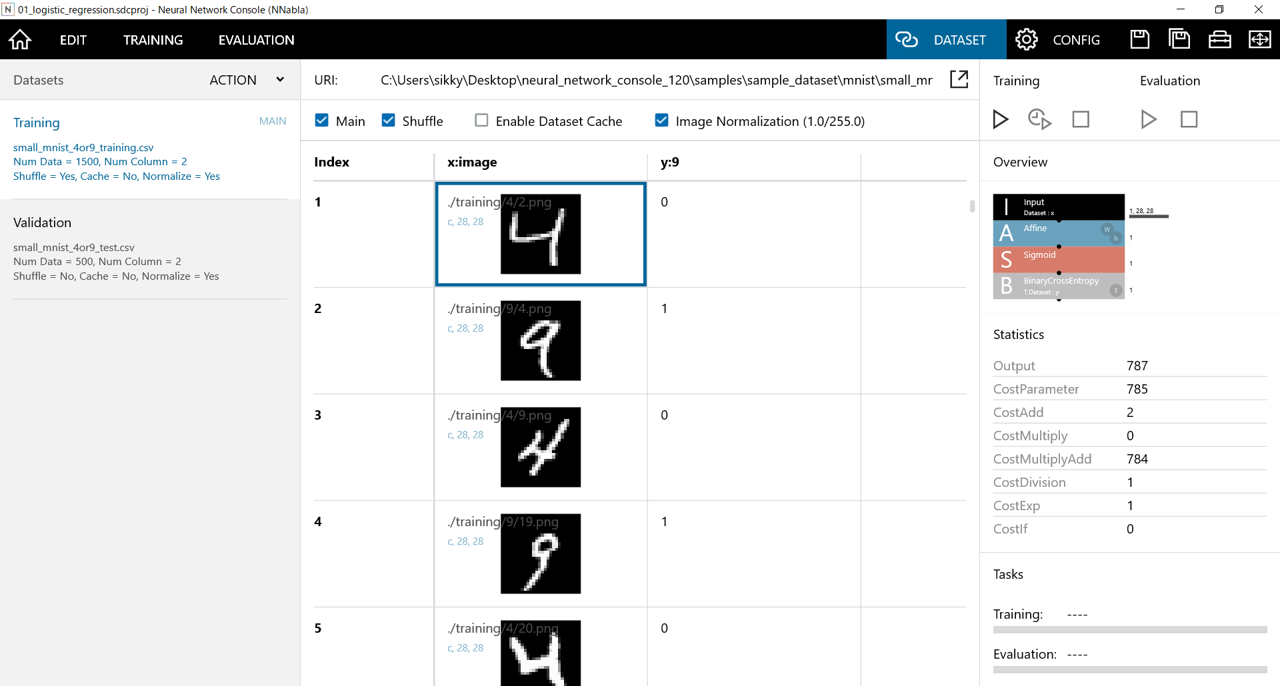 「CONFIG」を選択すると学習パラメータを調整できます。
「CONFIG」を選択すると学習パラメータを調整できます。
エポック数、バッチサイズ数、モニタ間隔エポック数等が設定できます。
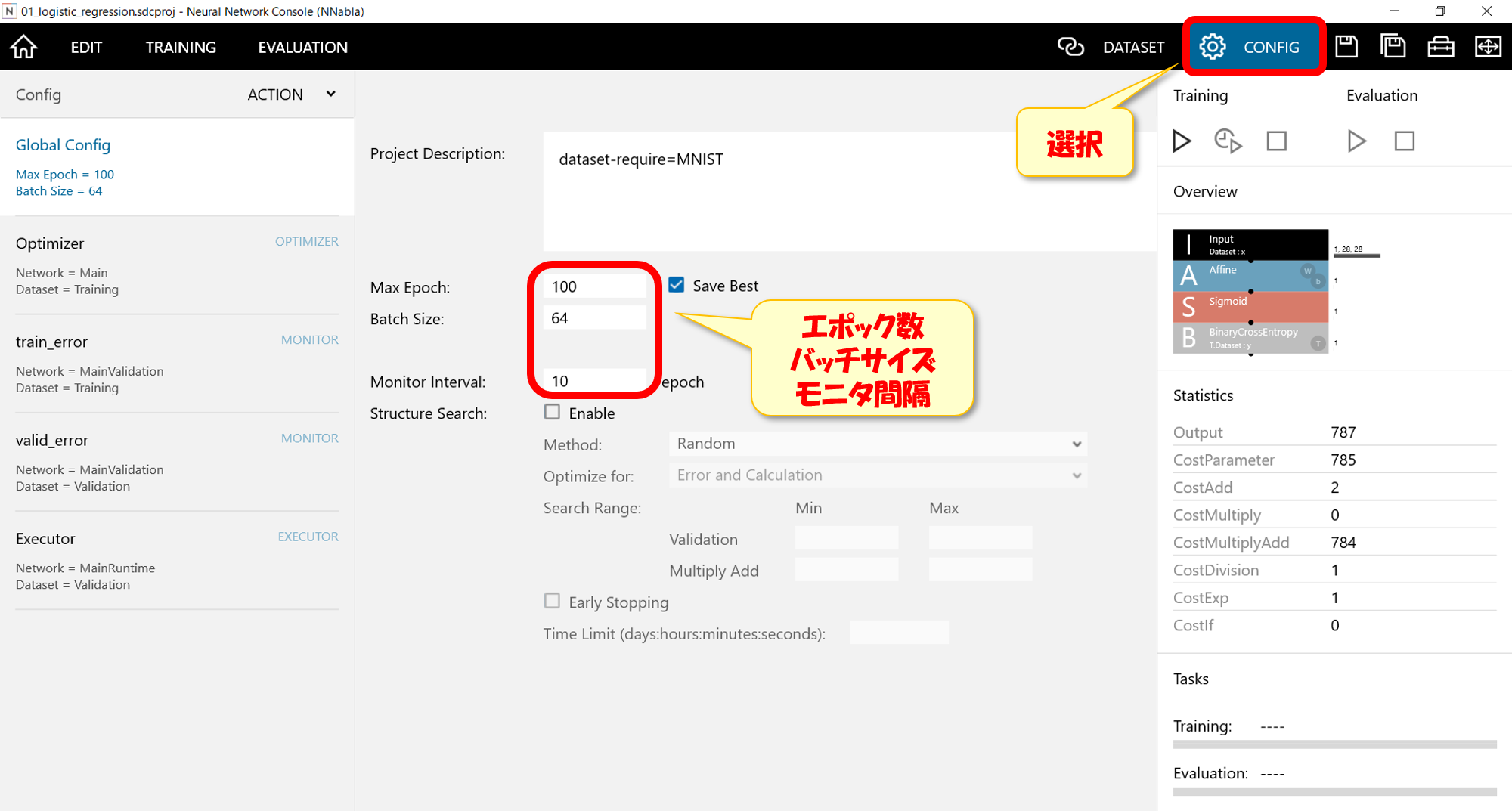
サンプルプログラムを実行
設定が完了したら実際にサンプルプログラムを実行する。左上の「TRAINING」を選択し、右側の三角マークをクリックすると、プログラムが実行されます。
また、プログラムの実行時間も表示される。今回の場合30秒程度で終了します。
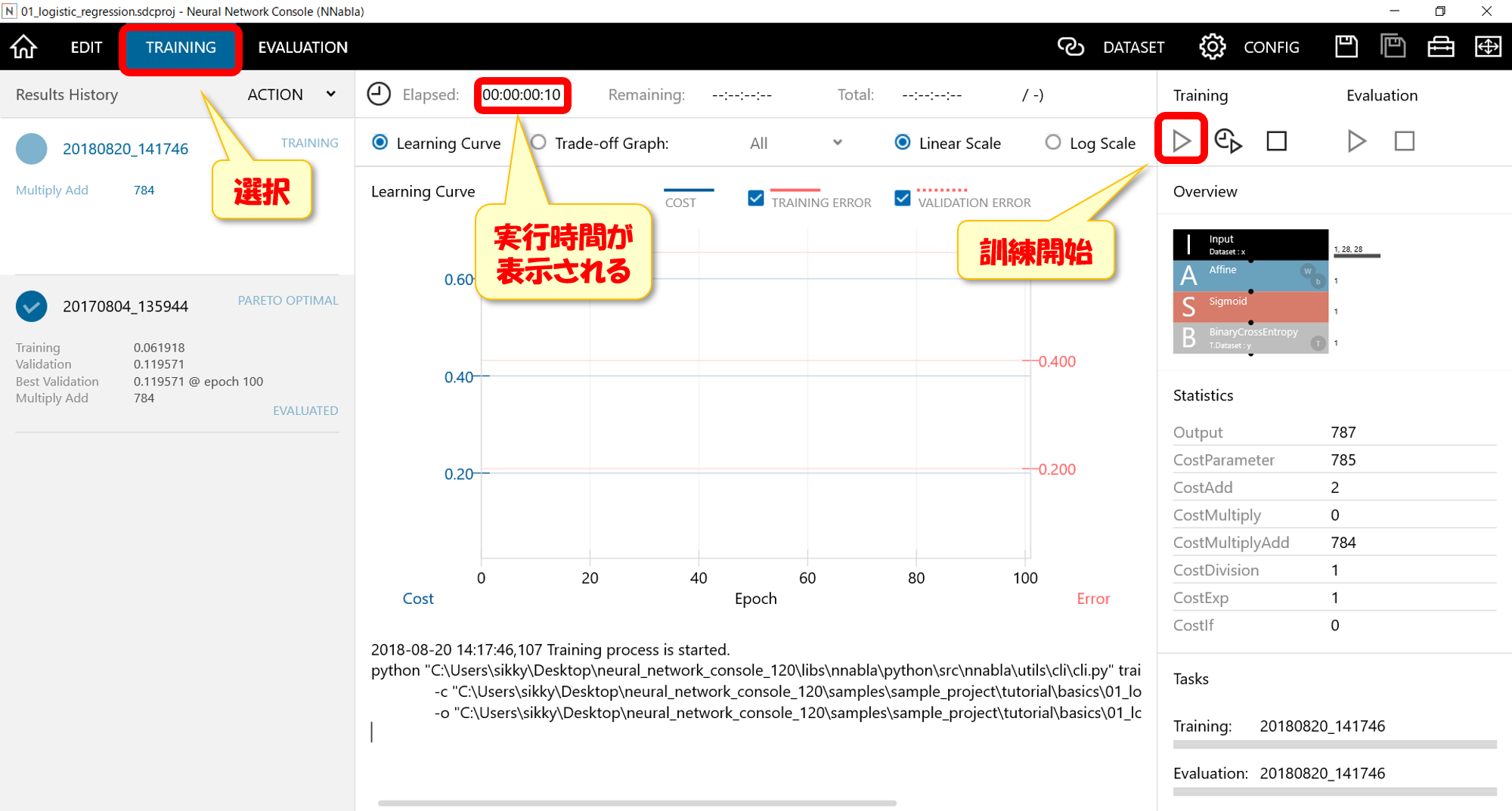 Neural Network Consoleの場合、リアルタイムで学習曲線が見れるので、視覚的にわかりやすい。実行後は下記のような画面になっています。
Neural Network Consoleの場合、リアルタイムで学習曲線が見れるので、視覚的にわかりやすい。実行後は下記のような画面になっています。
赤い実践が訓練データの誤差、赤い点線が検証データの誤差になっています。訓練データの誤差が小さくならない場合はモデルが単純すぎるケースが考えられるます。
訓練データの誤差は小さくなっているのにもかかわらず、検証データ誤差が逆に大きくなっている場合は、モデルが複雑すぎで過学習を起こしているケースになります。
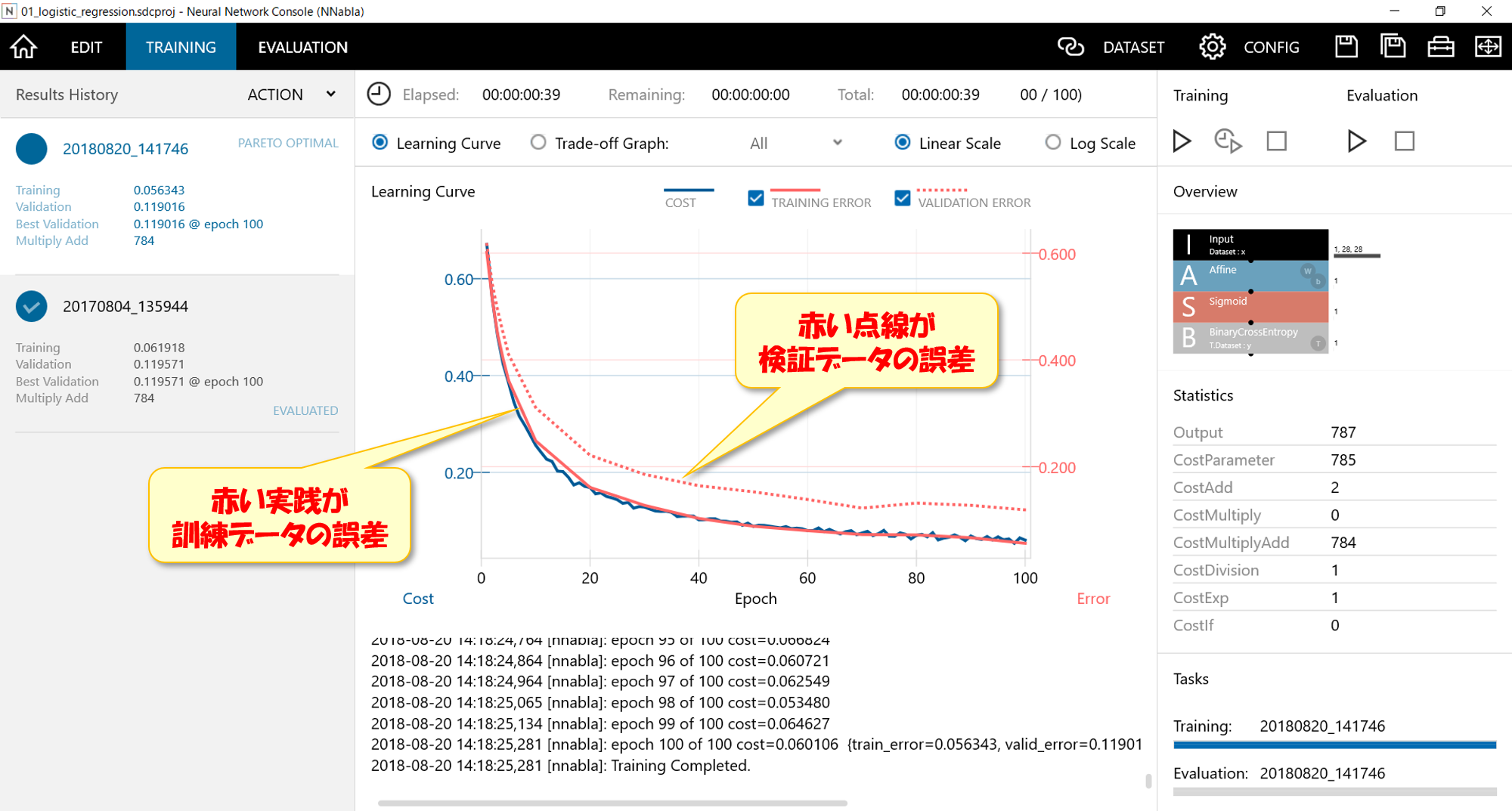 左上の「EVALUATION」をクリックすると、検証データを評価できる。検証データの結果はy’として数値化される。y’が0に近ければ「4」と判断し、y’が1に近ければ「9」と判断していることになります。
左上の「EVALUATION」をクリックすると、検証データを評価できる。検証データの結果はy’として数値化される。y’が0に近ければ「4」と判断し、y’が1に近ければ「9」と判断していることになります。
 結果を一通り見てみるとおもしろいケースがみられます。例えば下記に例を示します。
結果を一通り見てみるとおもしろいケースがみられます。例えば下記に例を示します。
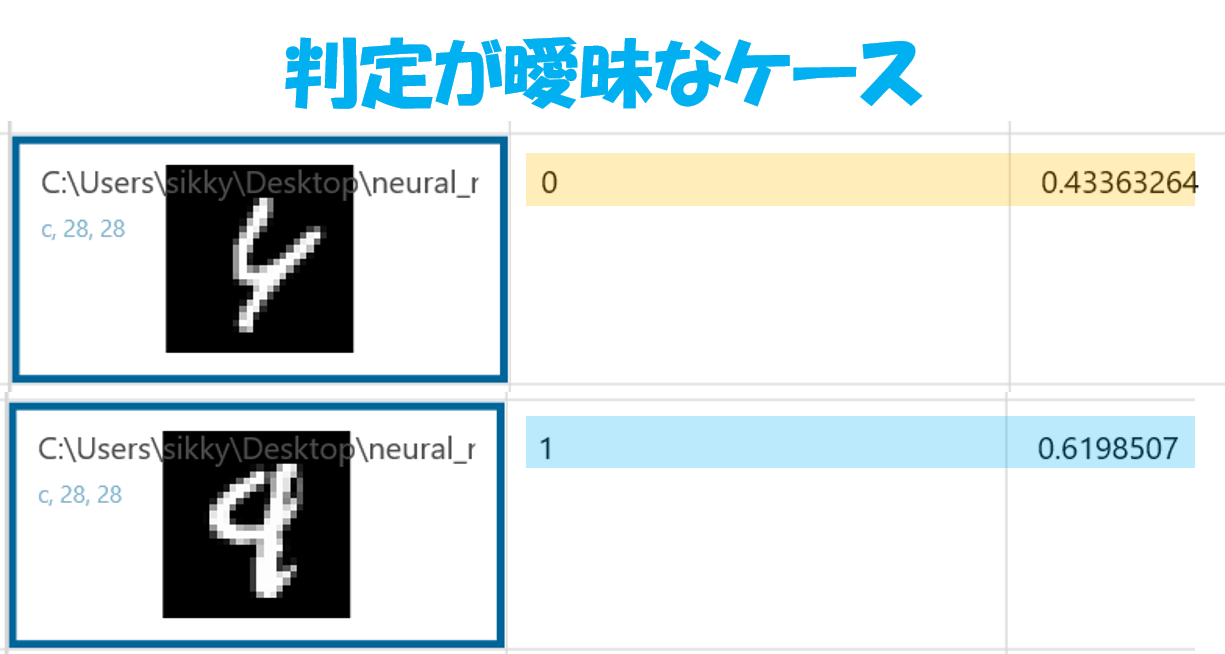
1つ目はy’=0.43と0.5に近い。0.5に近いということは「4」と「9」の区別がつかないということを示しています。0.43は0に近いので「4」と判断しているが、確かに元の画像を見ると理想的な「4」ではないのは確かである。
2つ目はy’=0.62となっている。0.62は1に近いので「9」とは判定しているものの、元の画像を見ると「4」に見えなくもない。
実際に入力画像と学習モデルが判定した数字を比較することで、新たな発見があるかもしれない。
Confusion Matrixを選択すると、それぞれのケースに対しての正答率を確認することができます。
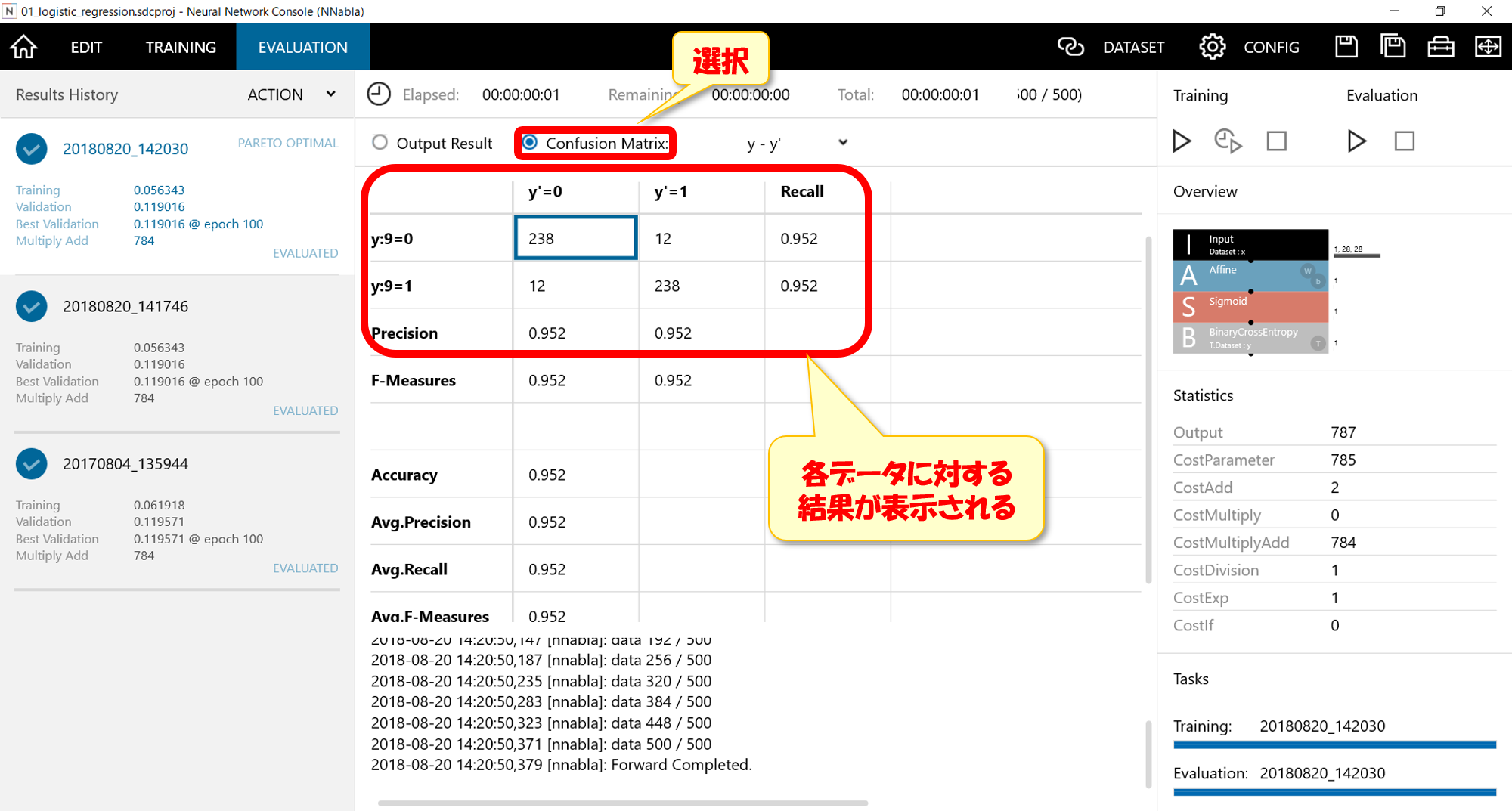
例えば今回だと下記4パターンが存在します。
- 「4」を「4」と認識する(238パターン)
- 「9」を「9」と認識する(238パターン)
- 「4」を「9」と認識する(12パターン)
- 「9」を「4」と認識する(12パターン)
たまたま1と2のケースのパターン数が同じであるが、このパターン数をもとに正答率を算出しています。
今回の記事は、ここで説明を終わります。
次回の記事では数字認識を用いて具体的な使い方の説明を整理しています。

コメント
コメント一覧 (1件)
ありがとうございます。
とっても参考になりました。