今回は機械学習の基礎となる手書きの数字認識をNeural Network Consoleで実装してみます。ファイルの読み込み方やモデルの作成方法などの説明に重点を置いているため、Neural Network Consoleの使い方がまだ分かっていない人の参考になればと思います。
なおインストールや基本操作に関しては前回の記事に整理していますので、参考にして頂ければと思います。
ディープラーニングに関する記事はこちら
読み込みデータについて
Neural Network Consoleで読み込むCSVファイルは、1行目はヘッダファイルであり、2行目以降にデータが続くという形になります。マニュアルには以下のように説明が記載してあります。
1 行目のヘッダの各セルは、CSV ファイルの各列のデータの変数名、次元インデックス、ラベル 名を示します。ヘッダの各セルの値は、変数名[__次元インデックス][:ラベル名]で表します。
変数名はNeural Network Console内での識別に用いる変数名を表します。変数名には任意の文 字列を利用することができますが、通常入力データには x、出力データには y を割り当てます。 入出力が複数ある場合はそれぞれ x1、x2…、y1、y2…のように、x、y の後に数字を付加して区 別します。y はx より右側の列に、x、yそれぞれの中では添え字が大きい変数ほど右側の列に配 置します。
次元インデックスは、ベクトルの形をした変数である場合に、CSVの各列がベクトルの何次元目 であるかを示します。次元インデックスは、変数名に続けて__(ダブルアンダースコア)と数字 で表します。インデックスは0 から始まり、例えば10次元のベクトルであれば 0~9の値を取り ます
今回の数字認識のデータは、独自で入手したデータとのファイル内にあるサンプルファイルのラベルを合成してデータを作成しました。xの次元数は784、yの次元数は10になります。訓練データ数30000、検証データ数12000になります。
実際のデータを見てみたい方は下記からダウンロード可能です。
ただしこのデータは今回使用した検証データのみになります。訓練データはサイズが大きすぎてアップロードできませんでした。
モデル作成方法
まずは新しいプロジェクトを作成します。New Projectをクリックします。
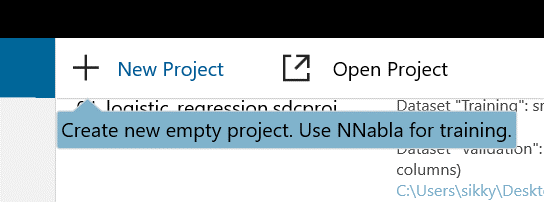 左上の「EDIT」ボタンをクリックすると、下のような画面になります。空白のスペースにモジュールを移動させてモデルを構築していきます。
左上の「EDIT」ボタンをクリックすると、下のような画面になります。空白のスペースにモジュールを移動させてモデルを構築していきます。
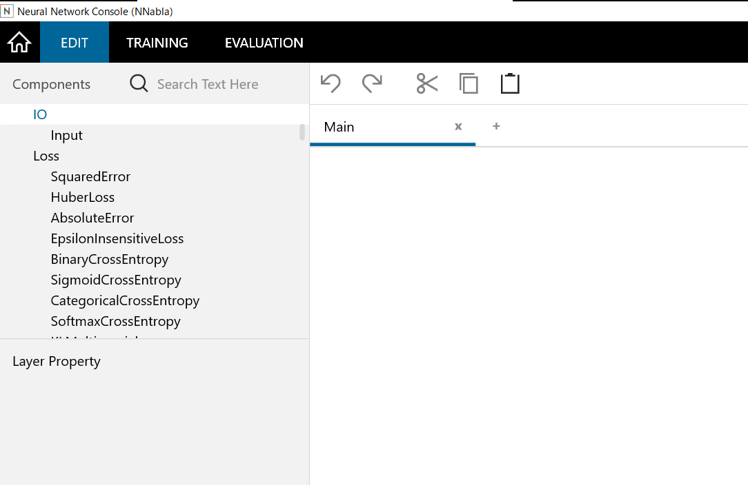 例えばインプットモジュールの場合は左側の一覧の「Input」をダブルクリックするとInputのモジュールが表示されます。
例えばインプットモジュールの場合は左側の一覧の「Input」をダブルクリックするとInputのモジュールが表示されます。
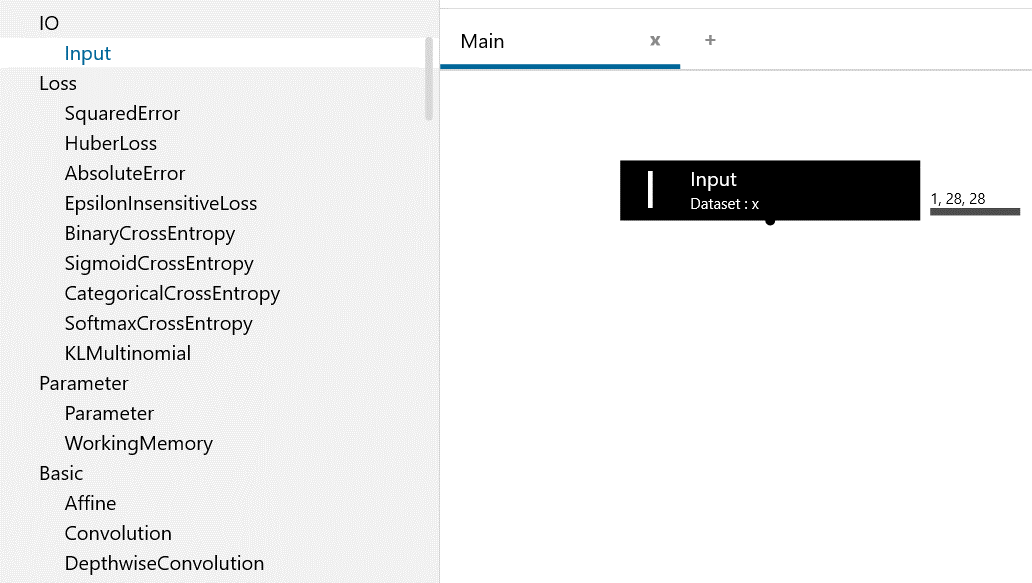 今回は下記のようなモデルを初期のモデルとして作成しました。
今回は下記のようなモデルを初期のモデルとして作成しました。
入力の次元数は784です。中間層1のノードの数は300、中間層2のノードの数は30、活性化関数はReLUを使用しています。また、データの出力は0~9までの10種類です。
0~9までであれば、4bitで表現できるのではないかと思う方もいらっしゃるかと思いますが、ニューラルネットワークで分類する場合、分類の種類数と同じ出力数を持たせた方が精度が良いという結果があるので、このようにあえて10種類の出力を用意しています。
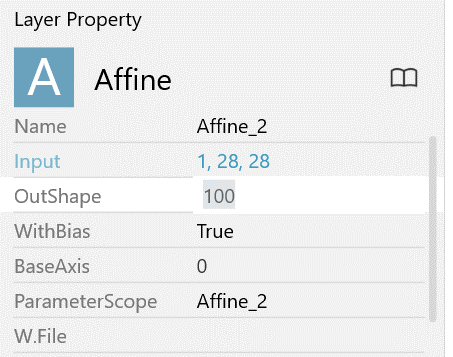
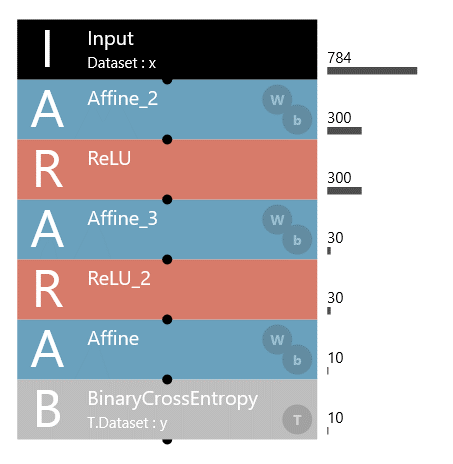 また、入力の次元数は画面左下にある下記画面にて変更することができます。OutShapeの数字をクリックして、変更したい数字を入力してください。
また、入力の次元数は画面左下にある下記画面にて変更することができます。OutShapeの数字をクリックして、変更したい数字を入力してください。
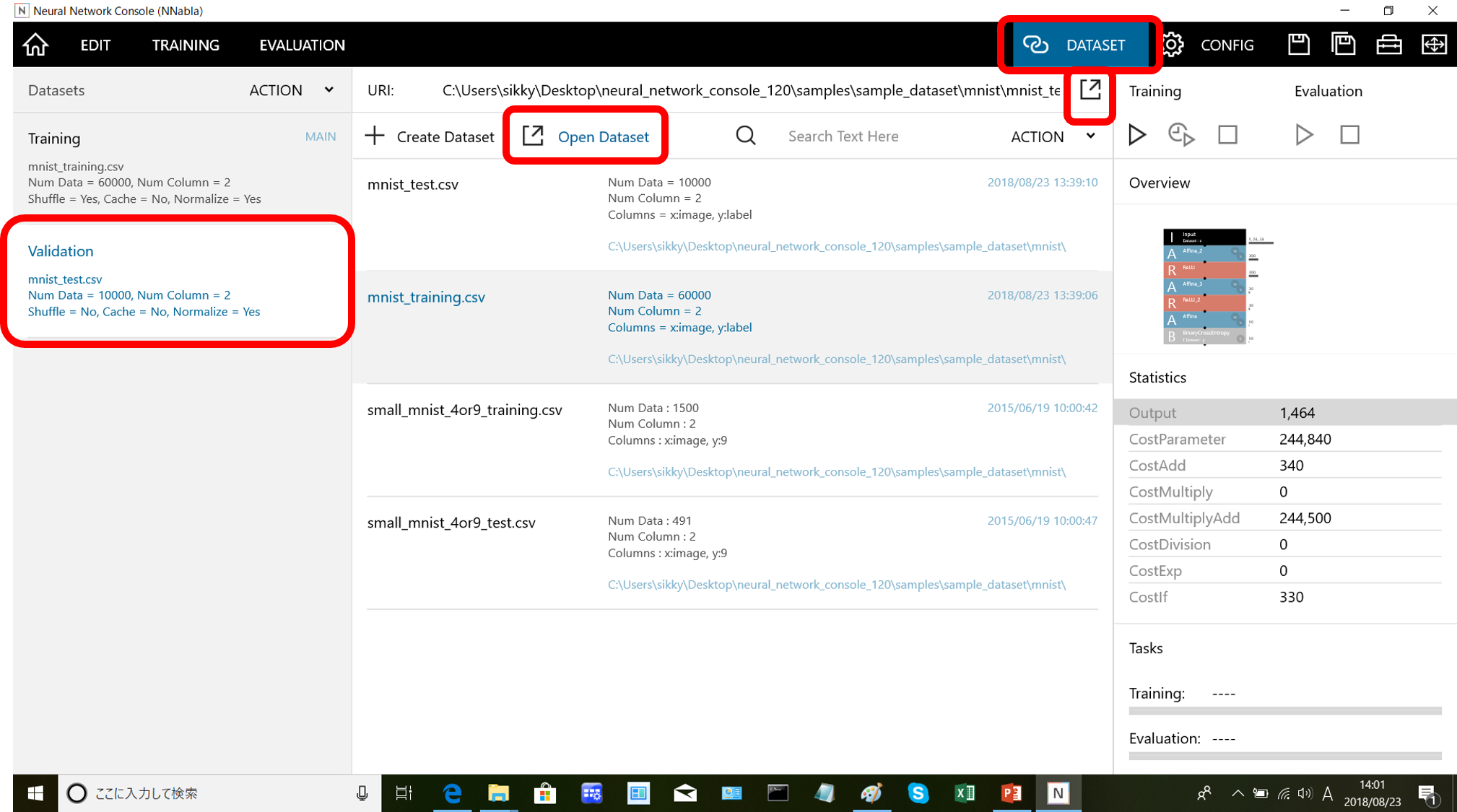
 モデルが完成したら次はデータを用意します。必要なデータは2種類で「訓練用データ」と「検証用データ」です。右上の「DATASET」ボタンからデータ読み込み画面に移ります。
モデルが完成したら次はデータを用意します。必要なデータは2種類で「訓練用データ」と「検証用データ」です。右上の「DATASET」ボタンからデータ読み込み画面に移ります。
左側の「Training」が検証用データで「Validation」が検証用データになります。
「DATASET」ボタン下のアイコンをクリックし、「Open Dataset」から読み込みたいファイルを読み込むことができます。
検証とモデル作成を繰り返す
初期モデルの作成とデータの読み込みが完了したら、次は検証とモデル作成を繰り返していきます。ここからが作業者の腕の見せ所でもあり、最も難しい部分でもあります。
右側の訓練開始の三角ボタンをクリックすると、学習が始まります。
※訓練を実施する前にプロジェクトを保存していない場合は、下記メッセージが表示されるのでOKボタンをクリックしましょう。
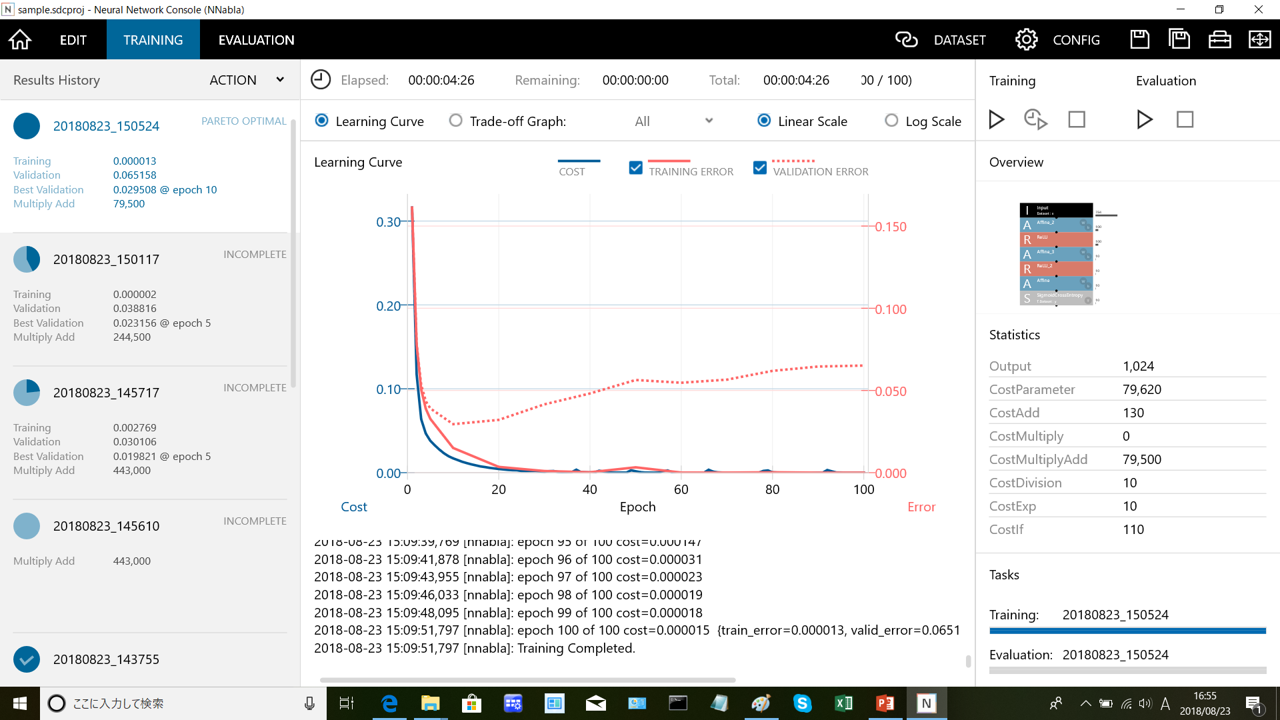
赤い実践が訓練データに対するERRORの推移で、赤い点線が検証データに対するERRORの推移です。この結果を見ると訓練データに対しての精度は良いのですが、検証データに対してはエポック数を重ねるごとに精度が悪くなっているので過学習を引き起こしています。こういうケースはモデルが複雑すぎるので、中間層の数を減らしたり、ノードの数を少なくするなどモデルの単純化を行っていく必要があります。
※追記
上記グラフのように検証データの精度が右肩上がりに悪化していったとしても、最終的な精度は問題ないというケースが見られました。なので、やや過学習をしているように見えたとしても、必ずしもモデルに問題があるというわけではなさそうです。
ちなみに「CONFIG」画面のところで、エポック数や学習係数など様々な学習パラメータが変更できますので、必要に応じて変更してみてください。
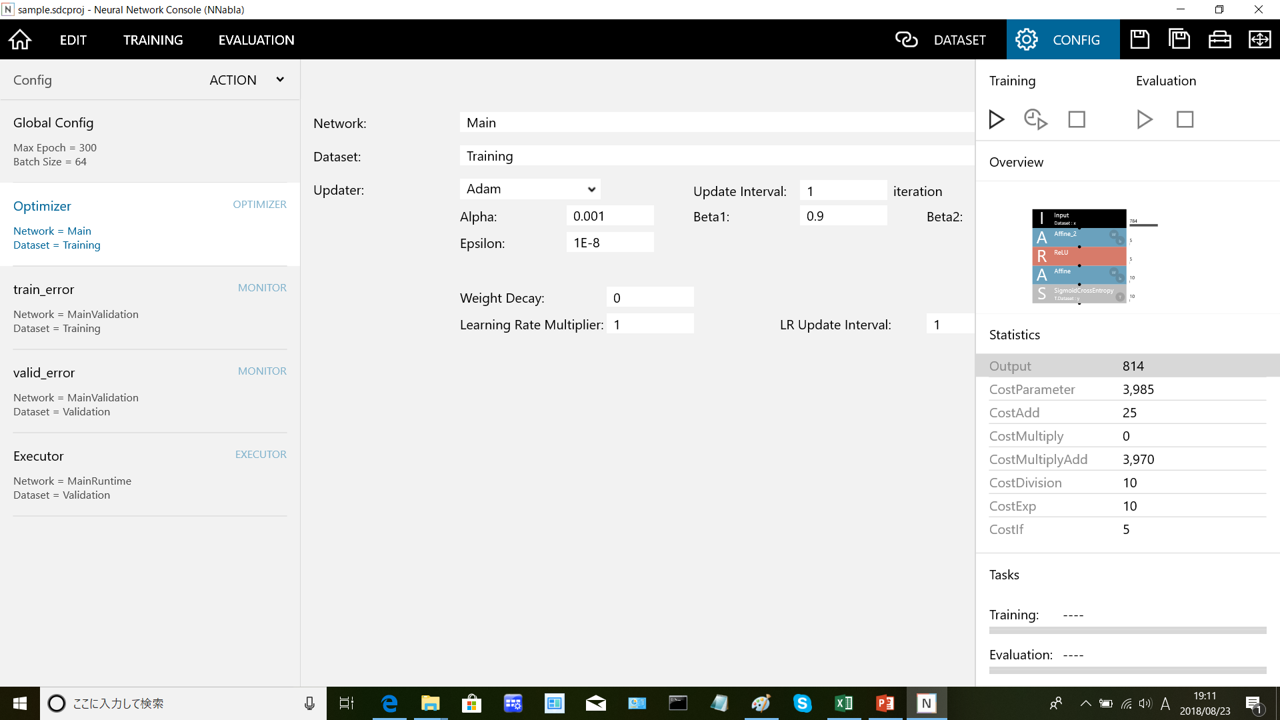
モデルの再構築
初期に作成したモデルは今回の数字認識に対しては複雑すぎたので、中間層の数を1つ減らし、ノードの数も減らし、最終的なモデルは下記のようにしました。
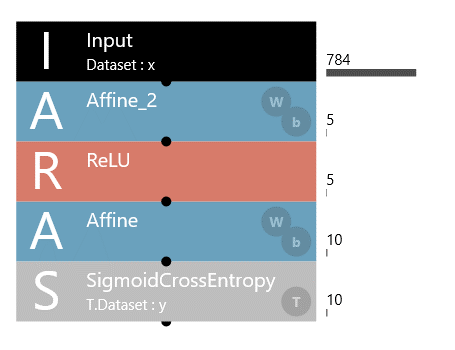 これを最終的なモデルとし検証結果を確認していきたいと思います。
これを最終的なモデルとし検証結果を確認していきたいと思います。
数字認識結果確認
最終モデルの学習曲線は下記のグラフのようになっています。
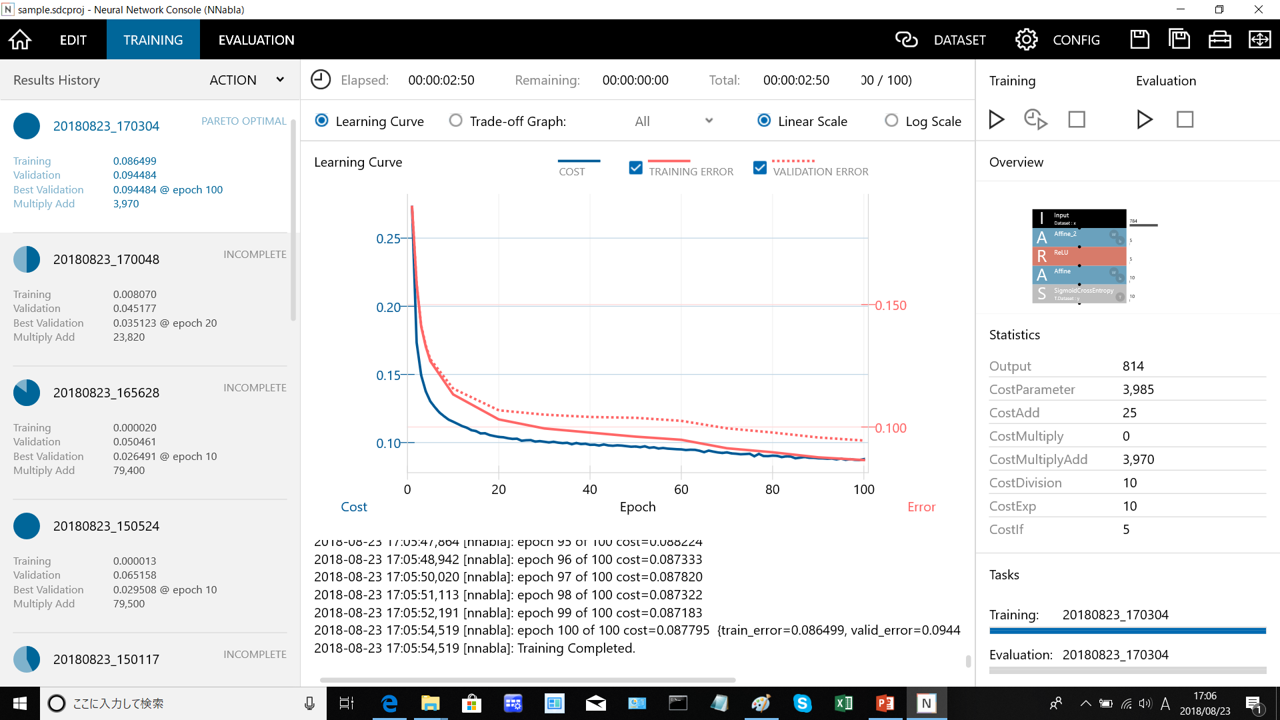
訓練データと検証データの両方のERRORが小さくなっており、学習曲線としては良好です。
訓練が終了したら、「Evaluation」の下の三角ボタンをクリックして、検証データの精度確認を行いましょう。Confusion Matrixを選択すると、精度を確認することができます。
ここで右クリックで結果をCSVファイルに出力することができます。
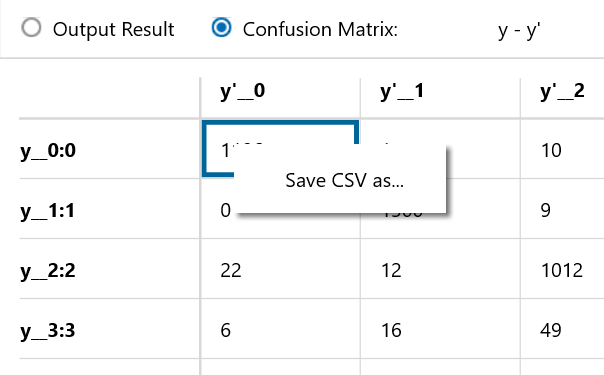
結果をまとめると以下のようになりました。yが対応する検証データの数で、y’がモデルが判定した数になります。
例えば検証データが「2」で、今回学習したモデルも「2」と判定しているケースは1012パターンあることになります。この表を見ると「5」の精度が良くないことも読み取れます。
また、その他に考察できる点としては「3」と「8」は間違えやすかったり、「6」と「7」の区別は完璧にできることなどが読み取れます。
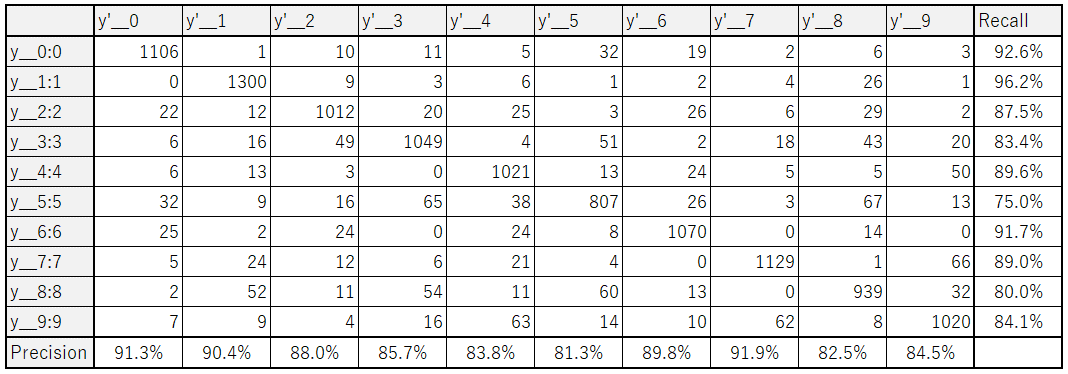
トータルの精度としては87%であり、数字認識のテーマとなると残念ながら不合格といった印象です。精度を上げるためにはモデルを改良していくか、データを増やすなど対策が必要になります。また、本来数字データであるため、フィルター処理等を事前に行うなどの工夫が必要になります。
今回はNeural Network Consoleの使い方に重点を置いたため、精度の追及は行っていません。数字認識の場合は95%以上の認識率は欲しいところですね。
次回の記事では活性化関数の違いを紹介します。

コメント